Feature Scaling: Intuition behind the math
I posted this article originally on Notion, sharing here to unify
We’ve all been asked to scale our features to speed up training & steadily decrease our cost. Ever wondered why scaling plays such an important role during model training? Let’s find out!
💭 This blog assumes that you are familiar with the concepts of cost function, gradient descent algorithm
In multivariate linear regression we deal with features. These features represent independent variables that have an effect on the dependent variable. Depending on the dataset, each of the features could have a different range of values. For example:
| area in sq.ft. | no. of bedrooms | price in $ |
|---|---|---|
| 1800 | 3 | 5000 |
| 1500 | 2 | 4500 |
| 2500 | 5 | 5600 |
The cost function for this data with two parameters would look something like this, assuming we use batch gradient descent with batch size of 3
If we simplify the above equation, all we have is a quadratic equation of the form
In our dataset, is a relatively large value when compared to . This makes the shape of the cost function such that will correspond to the narrow axis and will correspond to the long axis. The function plot will look something like this where axis represents and y axis represents
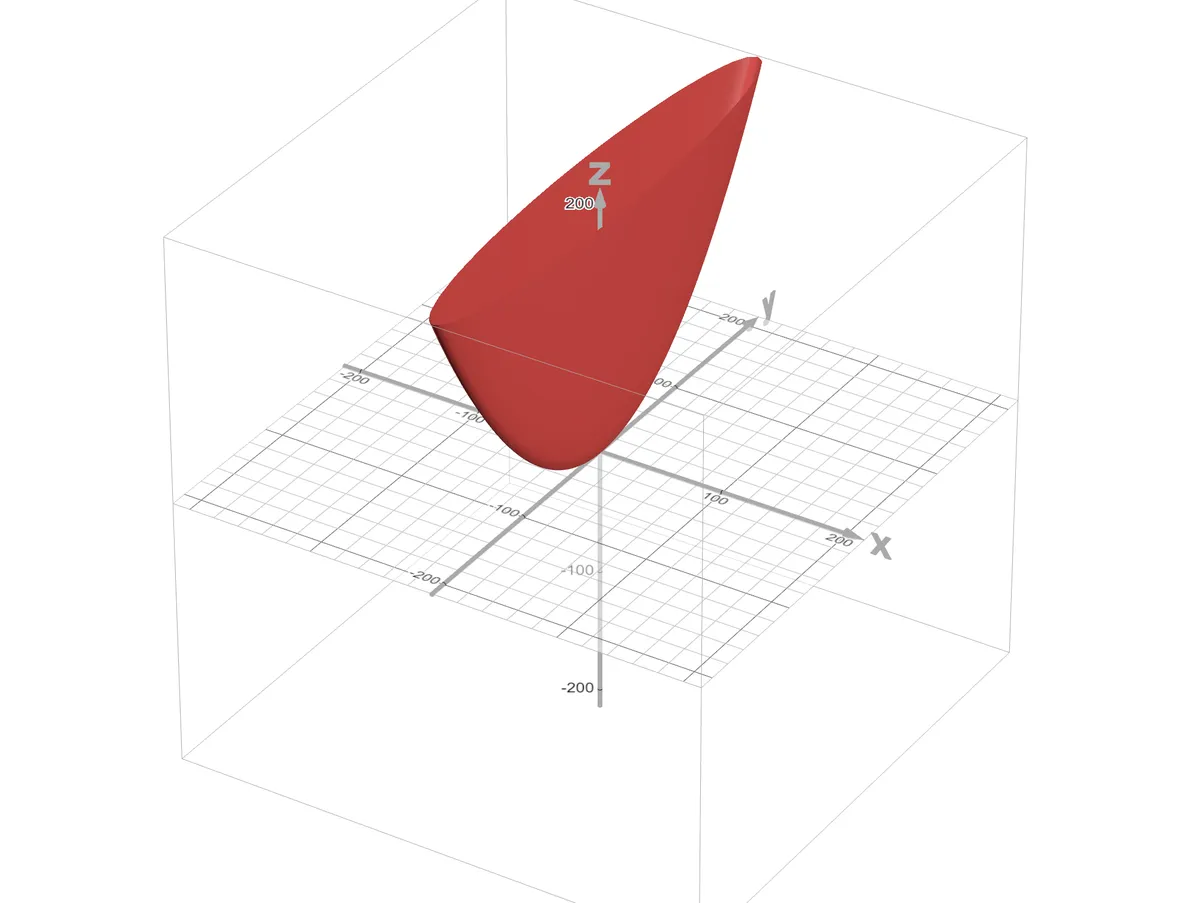 https://www.desmos.com/3d/wthv10wjki
https://www.desmos.com/3d/wthv10wjki
It’s clear that small changes in have a big impact on & relatively large changes in have a small impact. The rate of change of along the direction of each of parameter i.e., gradient components is given by
🧠 If is a multivariate function in , , a partial derivative of a function w.r.t. is just a way of asking how much does change w.r.t. while keeping constant.
Visually looks like this, keeping constant, where the plane cuts the 3-D curve
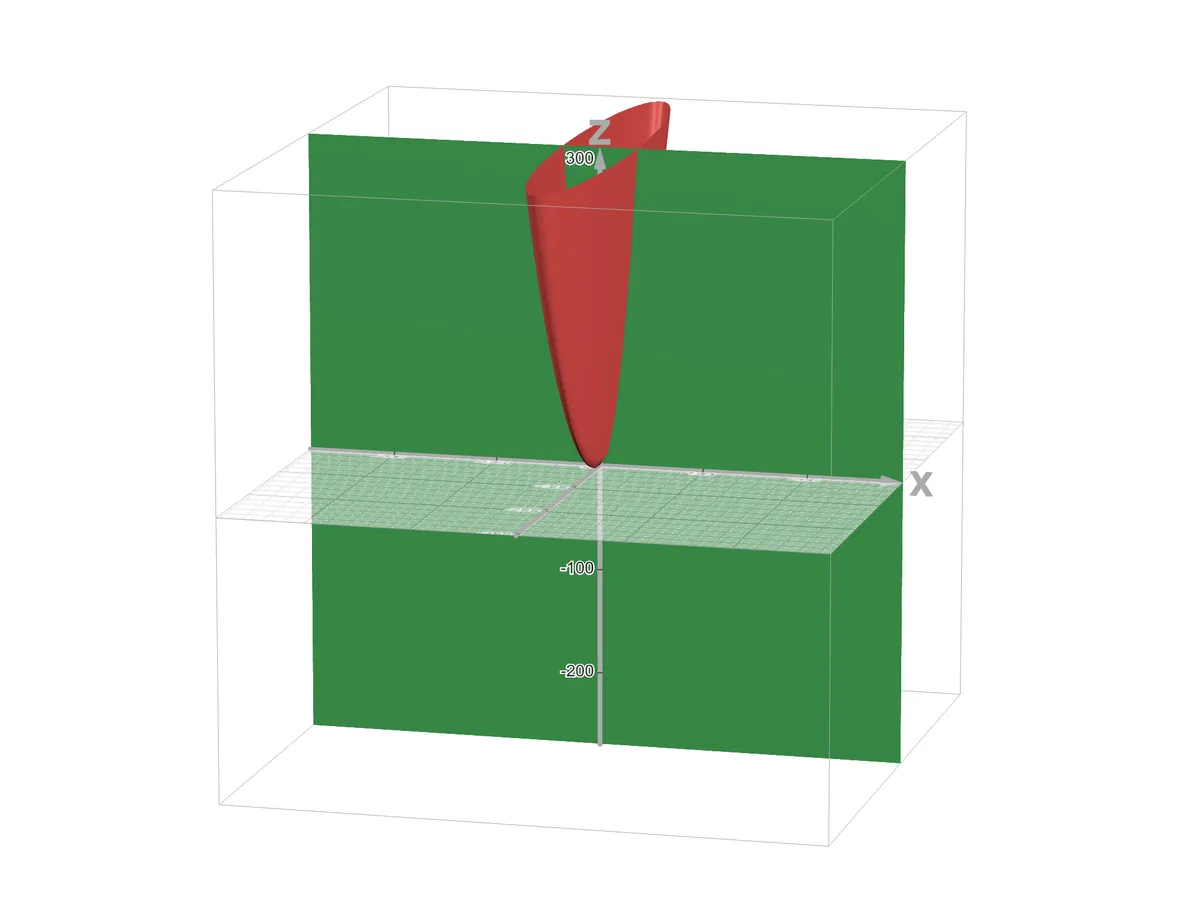 https://www.desmos.com/3d/yojzjugcw5
https://www.desmos.com/3d/yojzjugcw5
Visually looks like this, keeping constant, where the plane cuts the 3-D curve
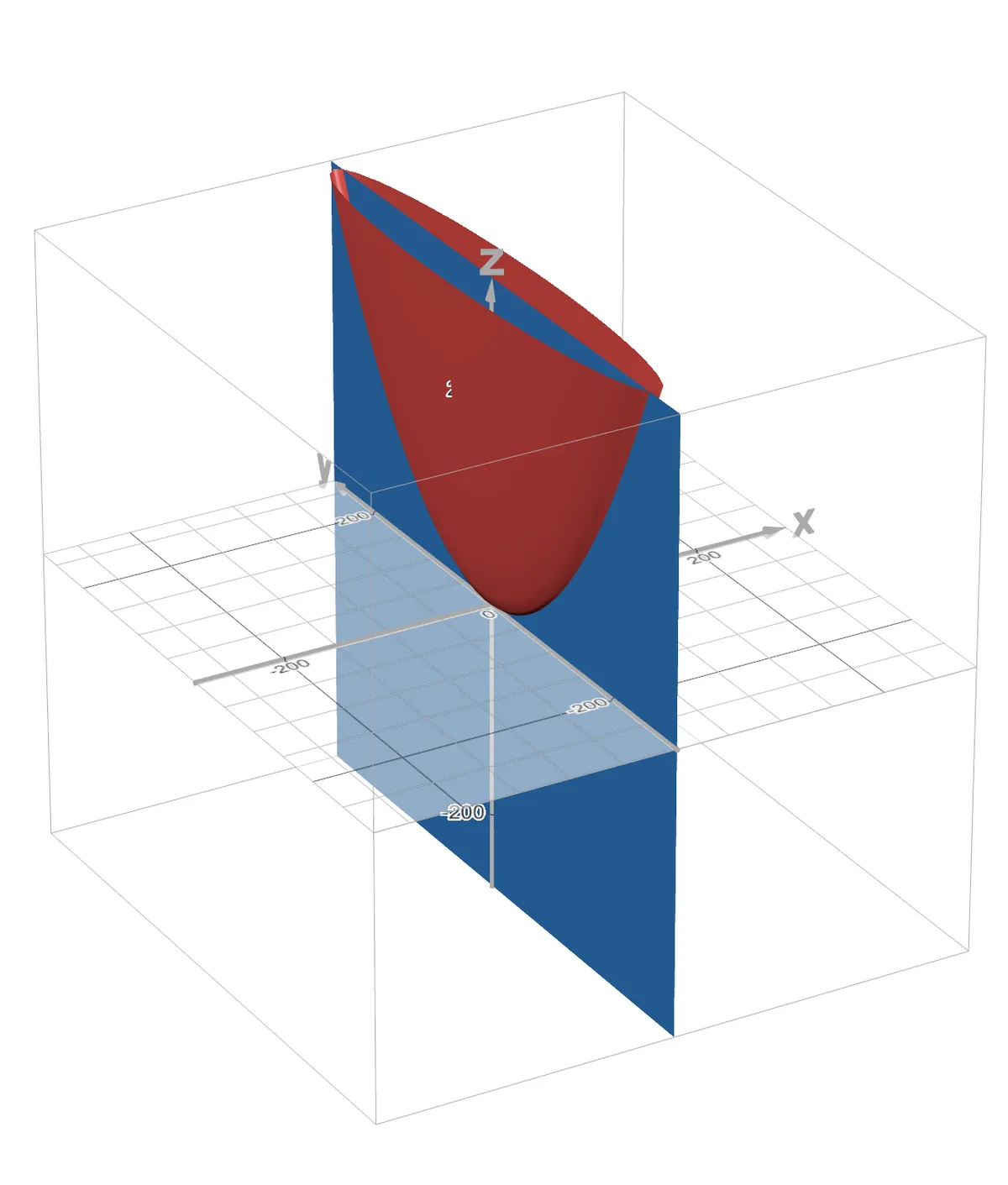 https://www.desmos.com/3d/kwp9c9zzrm
https://www.desmos.com/3d/kwp9c9zzrm
is larger as rate of change of is higher w.r.t. small changes in . Conversly, is smaller as rate of change of is lower w.r.t. small changes in . Visually, by imagining on a 2D axis, we can see that along the narrow axis (red), a small change has a huge impact on (vertical axis). Along the long axis (black), to change by the same amount, we need a relatively large change in .
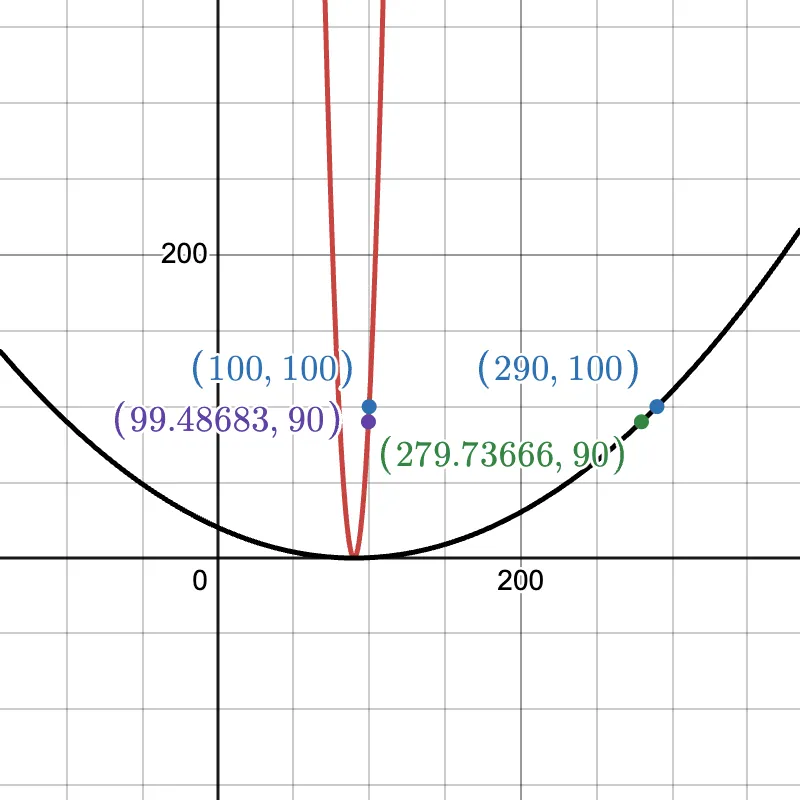 https://www.desmos.com/calculator/i6y8fwmd3m
https://www.desmos.com/calculator/i6y8fwmd3m
Let’s plug this information into our parameter update step using gradient descent
Faster convergence means having a relatively larger learning rate . But we run into an issue with his, if is too large, will overshoot as is also large. To counteract this, if we choose a relatively smaller learning rate , will update very slowly leading to a very slow convergence overall.
That is why we need to scale our features. Scaling helps us choose a good learning rate without having to worry about it’s effect on each of the parameters. This leads to faster & more stable convergence.
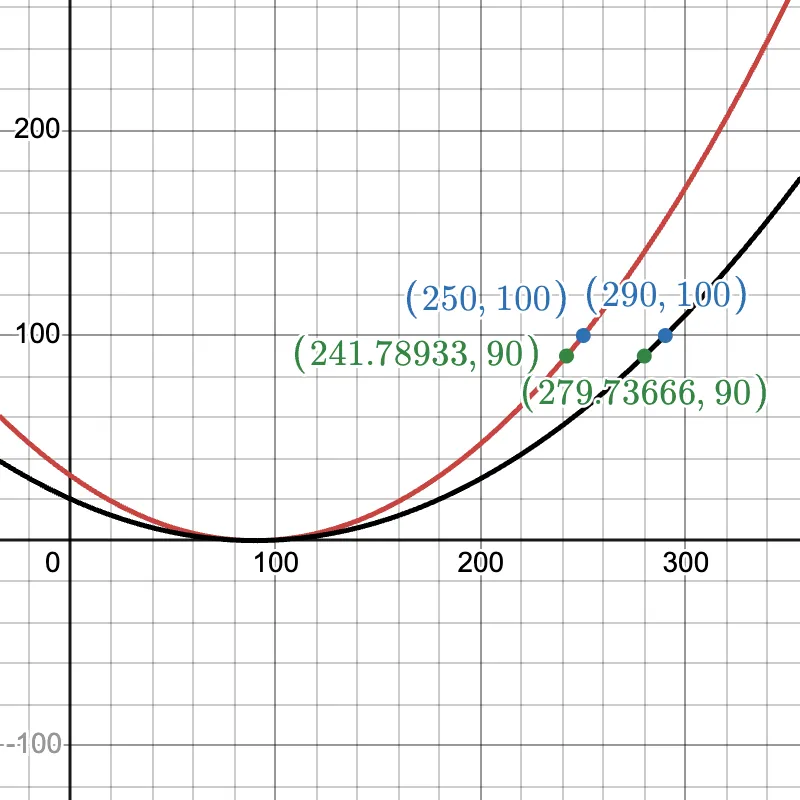 https://www.desmos.com/calculator/axjjlwtgyy
https://www.desmos.com/calculator/axjjlwtgyy
With Gratitude
To my family and friends for their support